Contextual disambiguation for improved conversational agents
Conversational agents or chatbots have been an interest of mine for a very long time. I wrote my first chatbot LIRA with a friend back around 2008. It used the Alicebot dataset to try and match what the user had said with one of the tens of thousands of pre-programmed replies.
In fact, all the program did was take the user input and remove a word from the end until the SQL query: This led to some funny responses albeit not very useful ones.
My latest attempt to understand natural language processing and produce a chatbot has been slow progress but there are two main ideas at the core of where I want to take the project.
To parse a sentence means to break the sentence into its components and generate the structure from a grammar (Find what rules make that sentence).
A grammar is a series of rules that define the structure of a sentence.
A parse tree is a representation of the sentence after the structure from the grammar has been added.
A great example from an article that explains these concepts in far more detail is the sentence “Fish fish fish” which means the animal, fish, engage in the act of fishing, other fish. Here is a great example of ambiguity in what the word means. Does the word fish mean the noun, representing the animal, or does it represent the verb to engage in the act of fishing. The article goes on to explore a sentence with even more fish which includes grammatical ambiguity as well as ambiguity in the meaning of the words.
A well used example of grammatical ambiguity is the sentence “I shot an elephant in my pajamas.” Here there are two ways to parse this grammar which lead to two very different scenarios being described. They can be represented by the following two trees:
The first talks about shooting an elephant while I was in my pajamas. Perhaps the elephant was attacking in the night.
The second talks about an elephant who is wearing my pajamas. A peculiar incident indeed.
Both understandings of the sentence are grammatically correct. You might assume that the ridiculousness of an elephant wearing pajamas would make the former the clear choice of disambiguation. However, the full extract from the Groucho Marx movie, Animal Crackers (1930) from which this sentence is taken is as follows:
“While hunting in Africa, I shot an elephant in my pajamas. How he got into my pajamas, I don't know.”
Sentences like this which are confusing to humans as well as machine systems may not be solved by the system I seek to create here, but I hope that they can be highlighted in such a way that the conversational agent can retort questioning the author of the ambiguity. Such as you might ask here “Was the elephant really wearing your pajamas?”.
Even without an understanding of who commonly wears whose pajamas the system should be able to identify the ambiguity in such a way to ask “Who is wearing your pajamas?”.
In the article, from which I’ve been taking these examples, it talks about the number of possible ways, to parse the sentence into a tree, grows with the Catalan numbers. Although I don’t doubt the maths presented in the article, I am interested to see the point at which sentences become intractable to disambiguate. Clearly, if the number of trees is as small as with the pajama joke (2 trees) then complexity is manageable.
I also wonder if using a technique whereby the parse trees are generated lazily it would be possible to rule out large branches of possible trees (Vegetation analogy perhaps becoming overloaded here).
The example the article gives for a ridiculously large sentence that even a child could parse with ease, is a 54 word example from Winnie the pooh. I feel that such extreme examples are rare and that by making the assumption that the sentences are short enough that their grammar can be calculated, I think some interesting level of understanding by the machine could be generated.
To produce the grammar I was basing the code on my understanding of this computerphile video which talks about top down and bottom up parsing. My current progress is held in this repository on github.
The current state of my parsing program uses the concepts of “Primitives” and “Composites”. The grammar is made from a top level Composite, the sentence, which then contains a list of options. Each element in the list of options is a collection of primitives and composites. Those composites themselves can contain primitives and composites.
The primitives will match a particular token of the input string. In the chatbot, these tokens will be words broken into their word types, (Noun, Verb, etc).
In my testing so far I have used only simple tokenized lists containing a few letters and simple grammar over those letters.
Currently, when consuming a grammar the system generates the possible matches from the ways the grammar can be parsed.
I think that it would be interesting to see how much you could summarise the corpus with entries such as NP VP. Such as both entries fit.
This would allow you to have the chatbot respond to a much larger number of queries with a much smaller corpus of examples. I know from reading about the current leading chatbot that elements of this parametrization are already being introduced.
To become more general still I have an idea for using a knowledge graph system.
At first I would like to try just a global knowledge graph system where every user’s statements are believed and added as entries in the graph. This graph could then be used to help disambiguate the sentences (to reduce the problematic numbers from the first section).
A way in which I would like to extend the knowledge graph structure is having a separate knowledge graph tracking the contextual content of the conversation so that the conversational agent could understand relevant references.
The best current systems which hold context, store only one value. For example, if you are talking about a car they may understand the context to be about the car, however, they wouldn’t be able to branch out from that to talk about how you might use your car to get around. Using a knowledge graph the links between concepts could be built up through conversation.
I have done some work on creating a general knowledge graph based chatbot which can be found in this repository on github however the work is very limited.
The system can currently learn about relations that it is taught and recall the list of relations connected to a concept.
There are some differences between how this graph system works and other knowledge graph based systems in that it is much closer to RDF triples.
In fact I think a good long term storage of the graph would be using RDF triples.
The data structure used in the system however links the entities together using directional links where the labels on these edges are themselves nodes in the graph.
As you can see from the diagram below the relationship between car and wheel is of type has. This indicates that a car has wheels.
I feel the advantage of this approach is that entities are defined by their relations to other things and not using some arbitrary definition system.
This should make it easier to do machine translation because if the context can be understood and this style of graph can be used to help disambiguate that, then the translation can contain more understanding.
In fact, all the program did was take the user input and remove a word from the end until the SQL query: This led to some funny responses albeit not very useful ones.
My latest attempt to understand natural language processing and produce a chatbot has been slow progress but there are two main ideas at the core of where I want to take the project.
To parse a sentence means to break the sentence into its components and generate the structure from a grammar (Find what rules make that sentence).
A grammar is a series of rules that define the structure of a sentence.
A parse tree is a representation of the sentence after the structure from the grammar has been added.
Dealing with ambiguous grammars
The first is the idea has to do with handling ambiguous grammars. One of the many problems with trying to understand natural language is the levels of ambiguity.A great example from an article that explains these concepts in far more detail is the sentence “Fish fish fish” which means the animal, fish, engage in the act of fishing, other fish. Here is a great example of ambiguity in what the word means. Does the word fish mean the noun, representing the animal, or does it represent the verb to engage in the act of fishing. The article goes on to explore a sentence with even more fish which includes grammatical ambiguity as well as ambiguity in the meaning of the words.
A well used example of grammatical ambiguity is the sentence “I shot an elephant in my pajamas.” Here there are two ways to parse this grammar which lead to two very different scenarios being described. They can be represented by the following two trees:
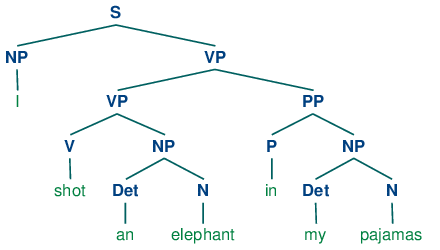

The first talks about shooting an elephant while I was in my pajamas. Perhaps the elephant was attacking in the night.
The second talks about an elephant who is wearing my pajamas. A peculiar incident indeed.
Both understandings of the sentence are grammatically correct. You might assume that the ridiculousness of an elephant wearing pajamas would make the former the clear choice of disambiguation. However, the full extract from the Groucho Marx movie, Animal Crackers (1930) from which this sentence is taken is as follows:
“While hunting in Africa, I shot an elephant in my pajamas. How he got into my pajamas, I don't know.”
Sentences like this which are confusing to humans as well as machine systems may not be solved by the system I seek to create here, but I hope that they can be highlighted in such a way that the conversational agent can retort questioning the author of the ambiguity. Such as you might ask here “Was the elephant really wearing your pajamas?”.
Even without an understanding of who commonly wears whose pajamas the system should be able to identify the ambiguity in such a way to ask “Who is wearing your pajamas?”.
In the article, from which I’ve been taking these examples, it talks about the number of possible ways, to parse the sentence into a tree, grows with the Catalan numbers. Although I don’t doubt the maths presented in the article, I am interested to see the point at which sentences become intractable to disambiguate. Clearly, if the number of trees is as small as with the pajama joke (2 trees) then complexity is manageable.
I also wonder if using a technique whereby the parse trees are generated lazily it would be possible to rule out large branches of possible trees (Vegetation analogy perhaps becoming overloaded here).
The example the article gives for a ridiculously large sentence that even a child could parse with ease, is a 54 word example from Winnie the pooh. I feel that such extreme examples are rare and that by making the assumption that the sentences are short enough that their grammar can be calculated, I think some interesting level of understanding by the machine could be generated.
To produce the grammar I was basing the code on my understanding of this computerphile video which talks about top down and bottom up parsing. My current progress is held in this repository on github.
The current state of my parsing program uses the concepts of “Primitives” and “Composites”. The grammar is made from a top level Composite, the sentence, which then contains a list of options. Each element in the list of options is a collection of primitives and composites. Those composites themselves can contain primitives and composites.
The primitives will match a particular token of the input string. In the chatbot, these tokens will be words broken into their word types, (Noun, Verb, etc).
In my testing so far I have used only simple tokenized lists containing a few letters and simple grammar over those letters.
Currently, when consuming a grammar the system generates the possible matches from the ways the grammar can be parsed.
Understanding from knowledge graphs
The second idea has two parts to it. First is based on the corpus of text that I used in that initial LIRA program which had 30k examples. Each example used literal words. This means that “My car is white”, and “My car is red” have to be two different entries in the database.I think that it would be interesting to see how much you could summarise the corpus with entries such as NP VP. Such as both entries fit.
This would allow you to have the chatbot respond to a much larger number of queries with a much smaller corpus of examples. I know from reading about the current leading chatbot that elements of this parametrization are already being introduced.
To become more general still I have an idea for using a knowledge graph system.
At first I would like to try just a global knowledge graph system where every user’s statements are believed and added as entries in the graph. This graph could then be used to help disambiguate the sentences (to reduce the problematic numbers from the first section).
A way in which I would like to extend the knowledge graph structure is having a separate knowledge graph tracking the contextual content of the conversation so that the conversational agent could understand relevant references.
The best current systems which hold context, store only one value. For example, if you are talking about a car they may understand the context to be about the car, however, they wouldn’t be able to branch out from that to talk about how you might use your car to get around. Using a knowledge graph the links between concepts could be built up through conversation.
I have done some work on creating a general knowledge graph based chatbot which can be found in this repository on github however the work is very limited.
The system can currently learn about relations that it is taught and recall the list of relations connected to a concept.
There are some differences between how this graph system works and other knowledge graph based systems in that it is much closer to RDF triples.
In fact I think a good long term storage of the graph would be using RDF triples.
The data structure used in the system however links the entities together using directional links where the labels on these edges are themselves nodes in the graph.
As you can see from the diagram below the relationship between car and wheel is of type has. This indicates that a car has wheels.

I feel the advantage of this approach is that entities are defined by their relations to other things and not using some arbitrary definition system.
This should make it easier to do machine translation because if the context can be understood and this style of graph can be used to help disambiguate that, then the translation can contain more understanding.



Comments
Post a Comment